# Introduction
Existing agentic benchmarks like Tau2 Bench [1] / Tau Bench [2], the SWE-bench family of benchmarks [3], AgentBench [4], or LiveCodeBench [5] evaluate specific tasks. The results of these benchmarks are not transferable or generalizable to tasks unrelated to the ones tested. This means that when creating new AI agents, picking an LLM that will perform best as the agent for the task often relies on performance heuristics or unreliable performance extrapolation from the sparse task-specific benchmark data available. This is especially bad for niche tasks where AI agents have not been benchmarked on any other similar tasks.
There are five foundational (classic) types of AI agents that most AI agents can be classified into (simple reflex, model-based reflex, goal-based, utility-based, and learning agents) [6]. Modern agentic workflows are built upon these foundational agent types or are hybrids of these agent types or are multi-agent systems built upon these foundational types/hybrid types. Since most agentic workflows can be classified using one or multiple foundational agent types, data on how well an LLM performs as each AI agent type is likely much more transferable/generalizable than task-specific data.
This project aims to create the first type-centric agentic benchmark. This benchmark will not only be useful to developers for selecting the right LLM for their agent type but also to researchers to better understand the agentic capabilities and limitations of existing LLMs, including how versatile or specialized each LLM is.
Other goals of this project are also to keep it well-documented, easy-to-use, and easy-to-extend as well as test Google Gemini and Gemma models on the benchmark.
# Methodology
For each agent type, I implemented a range of tasks that specifically test core capabilities associated with the agent type. I also aimed to closely follow best practices for building rigorous agentic benchmarks as outlined by Yuxuan Zhu et al.’s paper [7], which includes requirements such as making sure each task is solvable with correct ground truth, solvers are implemented for tasks, and setup does not change over time.
The codebase I created from scratch follows class-based object-oriented programming best practices, where a base benchmark class is used to scaffold and standardize structure of new tasks added to the codebase, making it easy to add new tasks. The codebase is structured to make it easy to add new benchmarks and models, thereby encouraging open-source contribution as the benchmark relies on having multiple type-specific tasks for each agent type and the more type-specific tasks we have the more generalizable the benchmark becomes.
As of the time of writing, I have implemented 15 agents/tasks as part of the core benchmark. I also created a validation framework for validating the predictive power of the core benchmark. The 15 agents/tasks that are as part of the core benchmark excludes the validation agents/tasks that can be used with the validation framework. This means we have 3 agents/tasks for each agent type for the core benchmark.
For each agent/task, we record the score (task-specific performance scaled from 0 to 1), execution time, and output tokens. Some tasks have their own task-specific metrics but the core metrics are the ones mentioned. Some of these metrics matter more for specific agent types or tasks. For example, execution time tends to be very important for simple-reflex agents as these types of agents are often designed to tackle tasks as quickly as possible. Token output is a proxy for the cost of using the agent (actual cost would need to be manually calculated using API rates or GPU usage costs that could change). Each task has around 8 to 21 scenarios which agents are evaluated on and there 188 scenarios in total across all tasks at this time of writing (excluding validation tasks). The score across scenarios for each agent/task is averaged to give a task-specific score and the agent-type-specific score for each agent type is the average of task-specific scores of tasks/agents that are of the same agent type. Below are some of the details of each agent/task I have implemented.
I implemented options to run the LLMs via their API (with configurable delay between API calls to prevent rate limiting) or locally (using vLLM).
## Simple Reflex Agents/Tasks
The key characteristic of a simple reflex agent/task is being able to respond to the current state (no learning, no internal model or memory of past states nor prediction of future states). Simple reflex agents/tasks typically also put emphasis on reaction speed. Below are the details of the simple reflex agents I implemented for the core benchmark.
Traffic light response agent/task (traffic_light): the agent is given descriptors of traffic light signals and must respond with the appropriate car action. In a real scenario, this agent could be used as a component of a traffic light response system with computer vision capabilities. This task only requires the current state of the traffic light and requires fast reaction speeds making it a good task to evaluate simple reflex agent performance. This is a basic reaction task emphasizing response speed.
Email processing agent/task (email_autoresponder): the agent is given detailed email scenarios and must respond with specific categories of response for the email. In a real scenario, this agent could be used as a component of a larger email response system. This task emphasizes the ability to react to signals amongst distractors within natural language.
Fraud detection agent/task (fraud_detection): the agent is given structured login/transaction logs and is asked to detect fraudulent activity/account takeover incidents. This task emphasizes the ability to react to signals amongst distractors within structured data.
Scores for these agents/tasks are just response accuracy. I deliberately separated execution time from the score since execution time could vary depending on the system hosting the LLM. In addition, having execution time as its own metric in this benchmark (and not part of the score metric) makes the score comparable between runs of the benchmarks on different systems. Execution time would only be reliable when comparing results obtained from running the benchmark in a controlled environment on the same system.
## Model-Based Reflex Agents/Tasks
The key characteristics of model-based reflex agents/tasks include maintaining an adaptable internal model of the environment and the ability to use this internal model to make informed decisions. This requires the agent to have good context memory and recall. Below are the details of the model-based reflex agents I implemented for the core benchmark.
Partially-observable maze navigation agent/task (textual_maze_navigation): Multi-step task where agent is given partial observation of environment state. The agent is placed in a maze and must reach the goal.The agent is given local observations (3x3 view around the model's position in the maze grid) each turn. The score is scaled 1 to 0 based on how many moves the agent took compared to the optimal number of moves (optimal number of moves / number of agent moves). This task emphasizes the ability to build an internal model of the environment’s state space from partial observations and context memory and recall.
Inventory management agent/task (inventory_management): Multi-step task where each item stock depletes in specific patterns. Each stock has a shortage threshold; the agent must deduce their depletion patterns and restock to minimize stock shortages each turn; agents must restock before depletion that turn but restock capacity per turn is limited. After depletion, scores are calculated each turn and averaged for the final score. Per-turn scores are scaled 0 to 1 based on how close the turn’s shortage is to the least and most possible shortage amount in that turn after stock depletion. Least shortage possible each turn is calculated by first considering the pre-depletion stock, applying depletion and allocating stock capacity greedily to items furthest below their threshold. Most shortage possible each turn is calculated by calculating shortage when a no restock capacity policy is applied. These calculations are done by a solver. This task emphasizes the ability to build an internal model of the environment’s transition function from partial observations.
Distributed-systems incident tagging agent/task (event_conflict_detection): Multi-step task where the agent must infer what issues (from a set of issues) are present from raw distributed system state logs. These issues are defined over a list of invariants and tolerances passed to the agent. The agent is encouraged to reason and re-evaluate its hypothesis as new data is provided to it each step. The final score is the micro F1 score of the issue tags reported by the agent in the final turn over the closed issue tag set. This task emphasizes the ability to iteratively improve hypotheses of the environment model through extended reasoning.
## Goal-Based Agents/Tasks
The key characteristics of goal-based agents/tasks include decision-making based on what actions would help the agent better achieve a goal, and the ability to effectively plan for future actions and/or adjust plans. Below are the details of the goal-based agents I implemented for the core benchmark.
Hotel-booking agent/task (hotel_booking): The agent is given a hotel booking request in natural language and must plan a comprehensive search for rooms on all combinations of search variables constrained by the booking request. The agent is scored from 0 to 1 depending on how comprehensive the search plan was as well as how efficient the plan was. A minimum correct search space is defined for each scenario and coverage of this minimum search space is scored from 0 to 1. An efficiency penalty is applied to this coverage score (depending on how many searches in the agent’s plan exceed the minimum number of searches required) to yield the final score. This task emphasizes planning comprehensiveness and efficiency.
Optimal fully-observable path planning agent/task (shortest_path_planning): The agent is given a directed weighted graph in the form of an adjacency matrix and is asked to find the shortest continuous path from the start to one or more goals. If there are multiple goals, the agent is required to visit every goal but in the shortest continuous path possible. Some of the graph inputs are very large. The agent score is scaled 1 to 0 based on how close the agent’s path length is to the optimal path length (score = optimal path length / agent’s path length). If the model provides an invalid path, it is given score 0. The model is encouraged to reason before answering. The optimal path is computed using a solver that runs Dijkstra’s algorithm from each start node and each goal node and tries every ordering of goal nodes. It calculates the total minimum path lengths for each ordering using minimum path length values for the path between the start and the first goal in the ordering and minimum path length values between each subsequent goal in the ordering that were computed from running Dijkstra’s algorithm earlier. This task emphasises the ability to do multi-goal long-horizon planning.
Local webpage navigation agent/task (local_web_navigation): The agent is given website navigation and interaction tasks that it must complete. The task uses a selenium MCP server for browser automation and the website is hosted locally. The local hosting of a website created specifically for the benchmark ensures that the website environment is controlled and unchanging allowing for reproducible results. There are two phases to this task: exploration and exploitation. During the exploration phase, the model has partial-observability of the website and must explore the website to gather information it thinks might be important to achieve the goal during the exploitation phase. During the exploitation phase, the agent’s state is reset and it must create an optimal action plan for achieving navigation and interaction tasks based on information it gathers during the exploration phase. The model’s final score is a score from 0 to 1, and is scaled based on how close the number of steps in the agent’s plan is to the optimal number of steps (score = number of steps in optimal plan / number of steps in agent’s plan). If the agent’s plan doesn’t help it reach the goal, the agent is given a score of 0. The optimal plan used in scoring is computed by a solver performing breadth-first search over an abstract state space that models the website’s behavior. The optimal plans are further verified by running them via on the website to make sure they work. This task emphasizes the ability to perform meta-planning because in order to do well, the agent must plan during the exploration phase to optimize planning in the exploitation phase.
## Utility-Based Agents/Tasks
The key characteristics of utility-based agents/tasks include decision-making based on outcome optimization where the outcome can be determined by one or multiple factors (i.e. optimize utility where the utility is a function of factors such as costs, risk, benefits, etc.). Below are the details of the utility-based agents I implemented for the core benchmark.
Task scheduling agent/task (task_scheduling): This agent must schedule tasks in a way that maximizes net reward given task costs and constraints such as time slot restrictions for tasks, task dependencies, and task duration. A solver that respects these constraints is also implemented to compute the optimal task schedule and the associated optimal reward. The agent is scored from 0 to 1 based on how close the reward it achieved was to the optimal reward. For an invalid schedule, the agent gets a score of 0. This task emphasizes the ability to perform constrained utility maximization.
Portfolio optimization agent/task (portfolio_optimization): The agent is given news articles (with distractors) and must infer which asset to allocate capital on in order to maximize expected net profits in the short term based on information from news articles. The score is scaled from 0 to 1 based on how close the agent’s achieved net profit is to the optimal net profit. This task emphasizes the ability to perform simple utility maximization from information inferred from natural language.
Manufacturing line pareto-optimization agent/task (manufacturing_line_optimization): The agent is evaluated on its ability to optimize discrete manufacturing line parameters against multiple competing objectives using a weighted utility function. The agent is given objective equations, constants, objective weights and constraints in each scenario and must reason to output manufacturing line parameters that will maximize the weighted utility function. The task uses a discrete parameter grid and a solver to compute the optimal utility, and the worst feasible utility. The score is scaled from 1 to 0 based on how close the agent’s achieved utility is to the optimal utility and the worst possible utility. Invalid outputs get a score of 0. This task emphasizes the ability to perform multi-objective pareto-optimization.
## Learning Agents/Tasks
The key characteristics of learning agents/tasks include continuous learning from data from the environment to improve decision-making, being able to learn from past data to generalize and make decisions on unseen data, and being flexible and able to adapt to and learn from data from a wide variety of tasks or environment dynamics. Below are the details of the learning agents I implemented for the core benchmark.
Ball drop physical simulation agent/task (ball_drop): The agent must decide when to drop a ball to hit a moving target. The agent learns from training episodes and is assessed based on its ability to improve its performance (reduce miss distance) over time and to generalize to unseen scenarios. In each episode, the ball’s offset and target velocity are randomized and provided to the model. The model is also given its history of past offsets and target velocities, along with the time it chose to drop the ball and the resulting displacement from the target when the ball hits the floor. I.e. The past training episodes and results are added to the in-context memory passed to the agent in future episodes. The physical rules behind the episodes remain constant; however, the physical constants and rules used for the simulation are deliberately chosen to be different to that of Earth and the agent is told to not to assume Earth’s physical constants apply. This is to prevent the model from just relying on learnt physical rules from its pre-training data and not in-context learning. After set intervals of training episodes, the agent is evaluated on a test set of episodes; let us call these test intervals. The score for each test episode is scaled from 0 to 1 and is given by: score = 1 - |displacement of ball to target| / |worst possible displacement for this episode|. The score for each test episode within a test interval is then averaged to give a score for that test interval. Each test interval is considered a scenario for this task (so the task-specific score is the average of the score for each test interval). This task emphasizes the ability of an agent to learn and generalize to make decisions on unseen data from fixed but unknown environmental dynamics as well as learning involving in-context memory.
Trading agent/task (simulated_market): The agent must learn to trade in different markets. Each market has different patterns and the agent must learn from a set number of training episodes before it is tested on a new set of test episodes. Each episode has a set number of time steps and the agent can choose to buy, sell or hold stocks in a timestep. The agent’s learning is facilitated by retrieval augmented generation (RAG). The agent can query its memory of past training episodes (that includes information on past market conditions, the agent’s associated past actions and outcome) to inform current decisions. The score is scaled from 0 to 1 and is based on the optimal PnL (profits and losses) and the worst achievable PnL. This task emphasizes agent flexibility and its ability to learn from a wide range of environmental dynamics as well as learning involving retrieval augmented generation (RAG).
Ecosystem dynamics learning agent/task (ecosystem): This task evaluates the ability of an agent to learn ecosystem relationships through building and maintaining a knowledge graph of species interactions in a fictional biological system. The agent must discover predator-prey relationships, growth rates, and carrying capacity effects by updating its internal knowledge graph across multiple episodes. The agent's learning is assessed based on population prediction accuracy. For each episode, the task provides current populations and an intervention (add, remove, double, or halve a target species), prompts the agent with the current knowledge graph and rules, parses the model’s predicted final populations and updated relationships, and then simulates ground truth population dynamics with a solver that is given the true ecosystem parameters and food web information. The knowledge graph is then updated based on the outcome. After set intervals of training episodes, the agent is evaluated on a test set of episodes; let us call these test intervals. For each test episode, the prediction error across species is converted into a score from 0 to 1. The test interval score is the average of the episode scores in a test interval. The task-specific score is the average of the score for each test interval. This task emphasizes the ability of an agent to learn using a knowledge graph.
# Results
The results below are the results of the core benchmark run using model APIs. A total of nine Google Gemini/Gemma models were tested.
## Results by model (per-agent metrics)
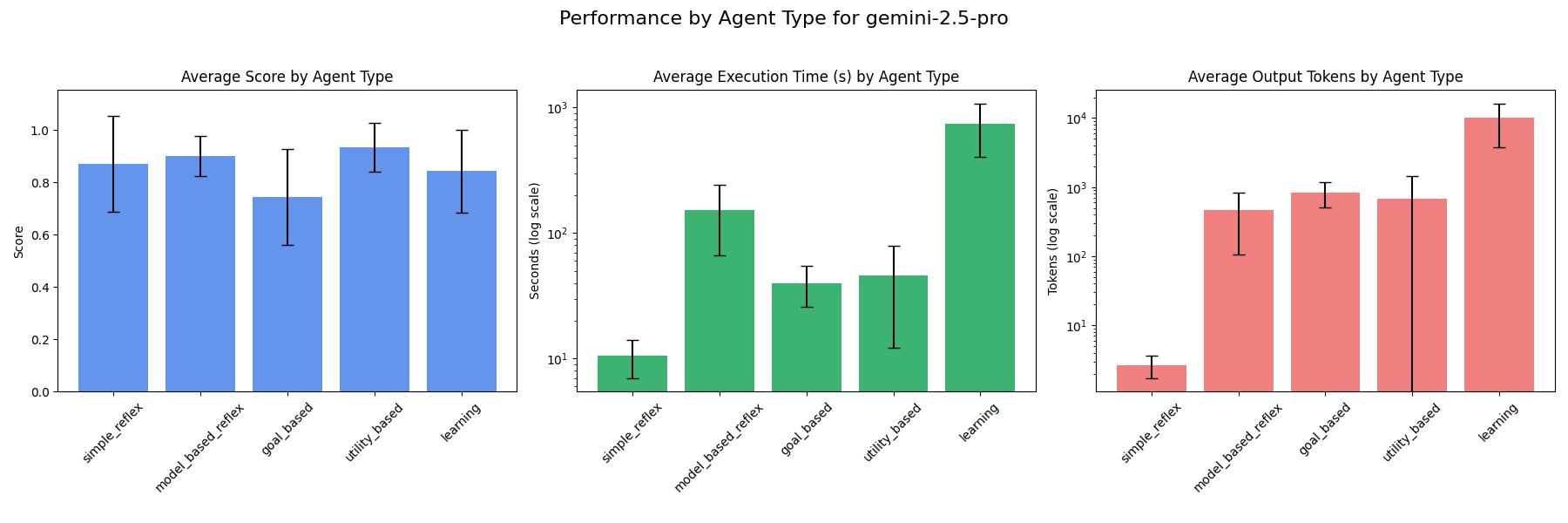
### gemini-2.5-pro
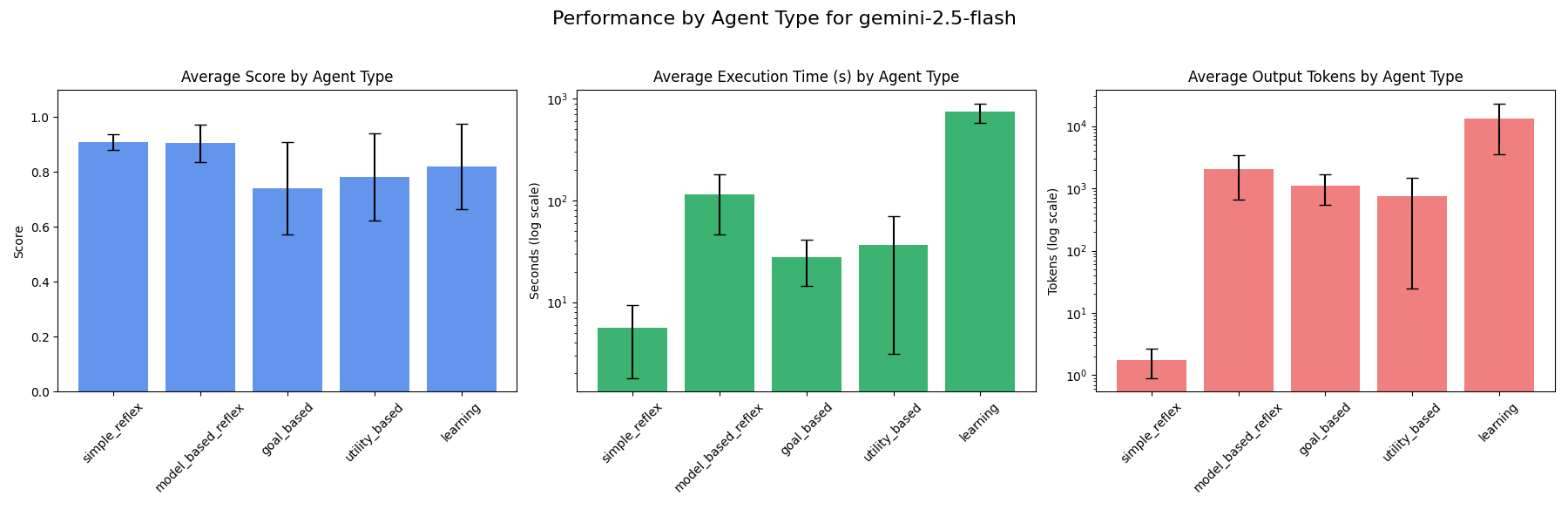
### gemini-2.5-flash
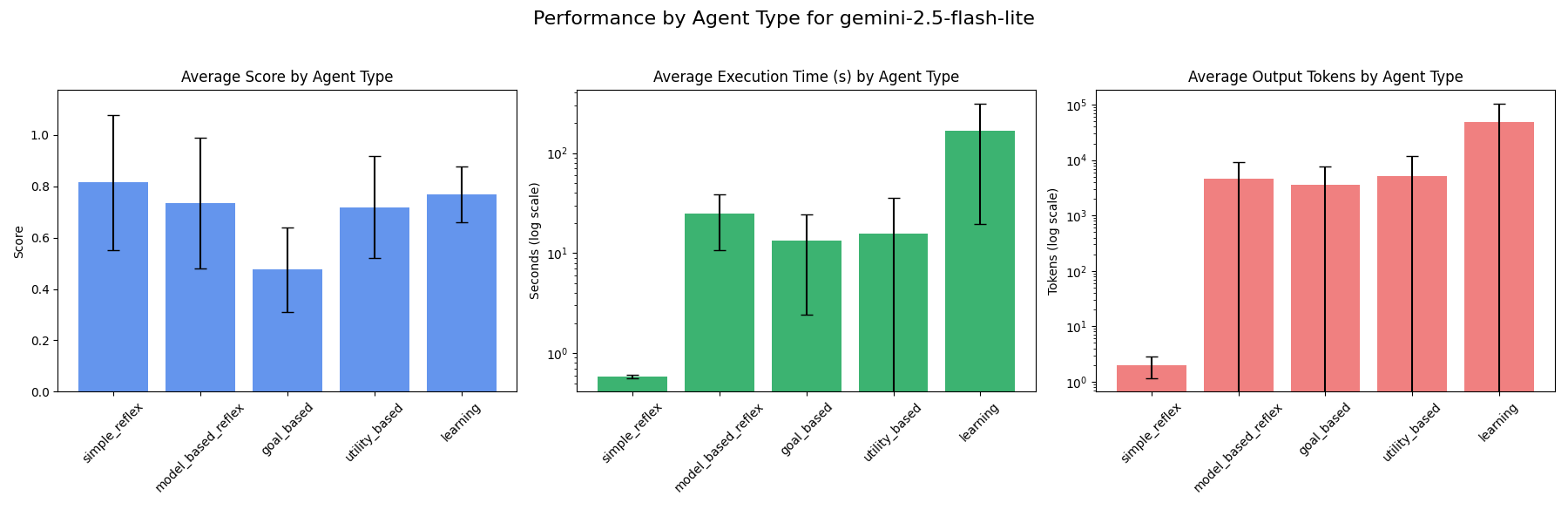
### gemini-2.5-flash-lite
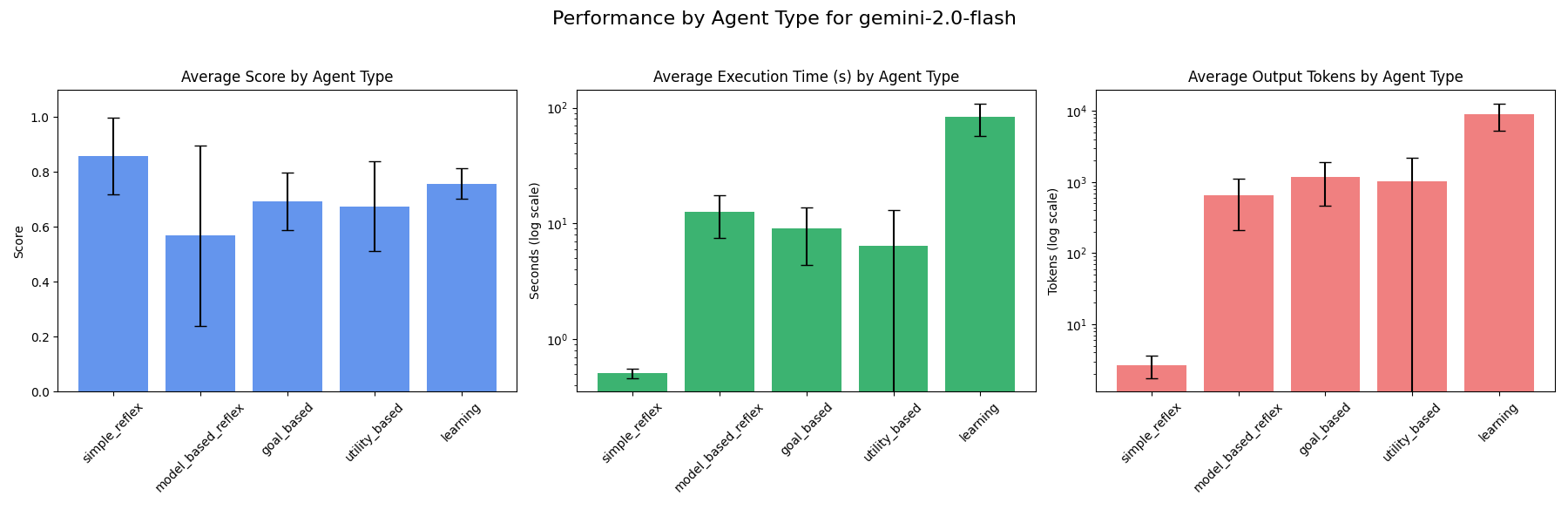
### gemini-2.0-flash
### gemma-3-27b-it
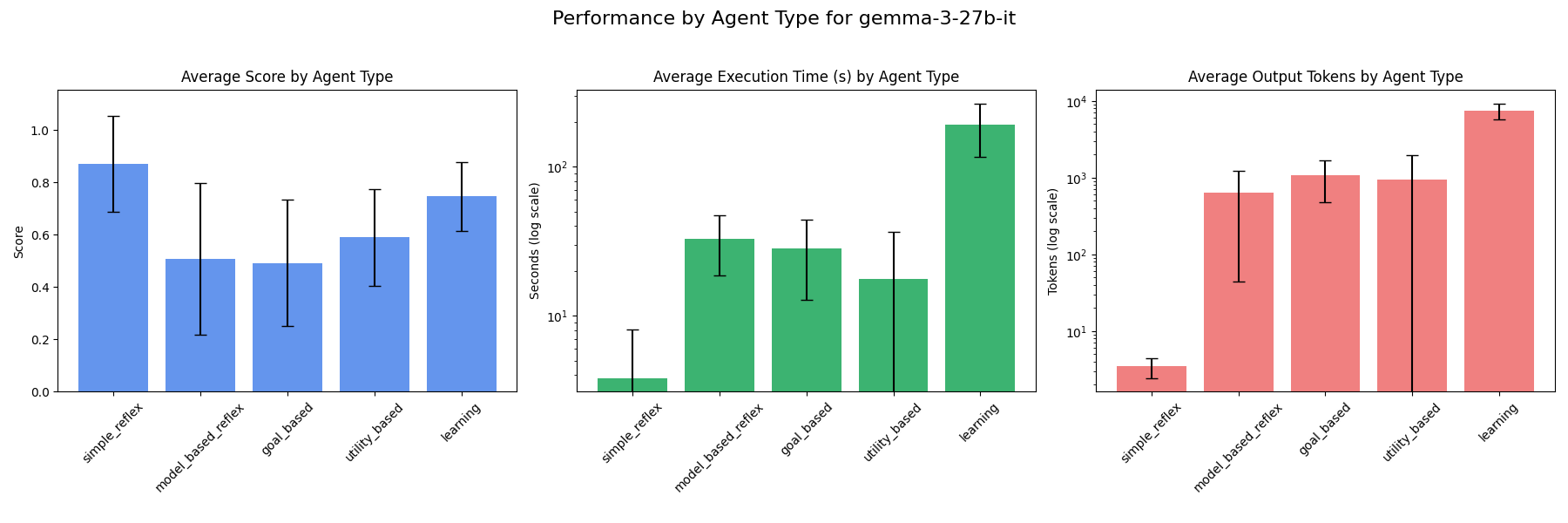
### gemma-3-12b-it
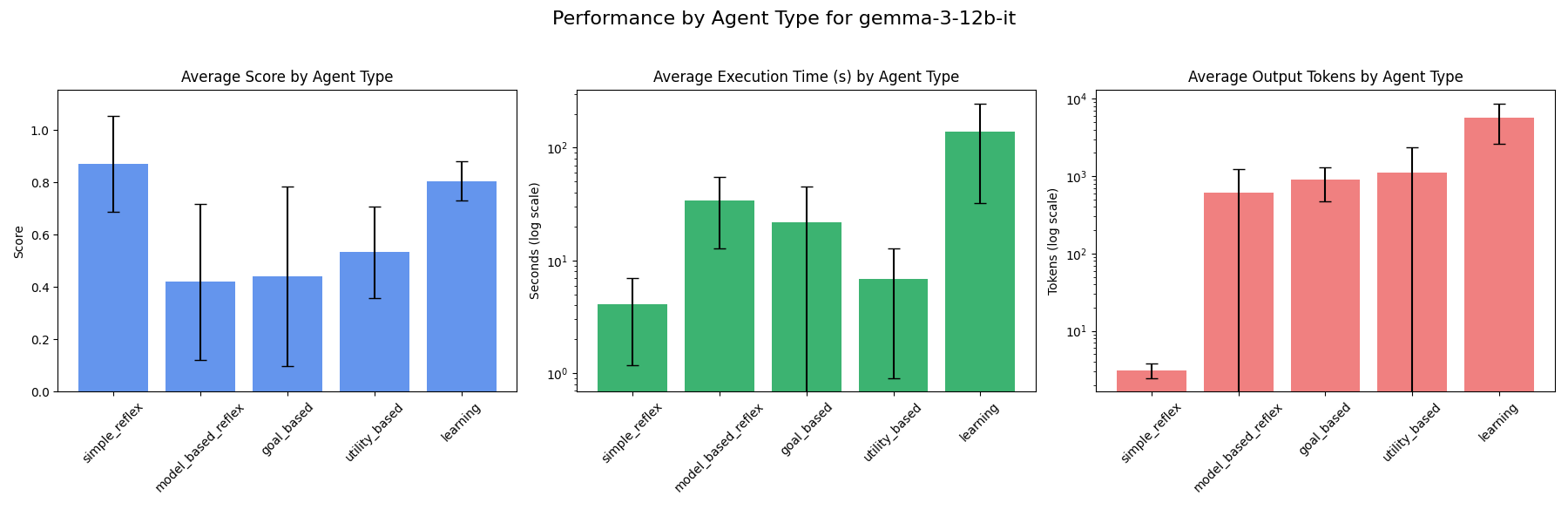
### gemma-3-4b-it
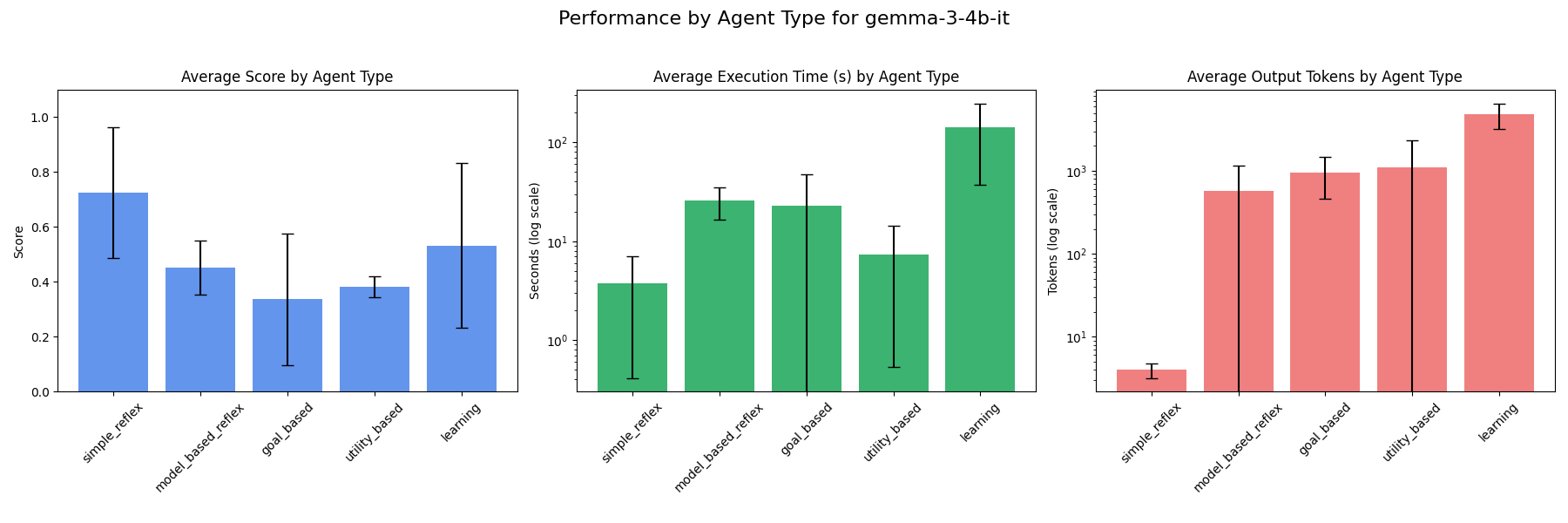
### gemma-3-1b-it
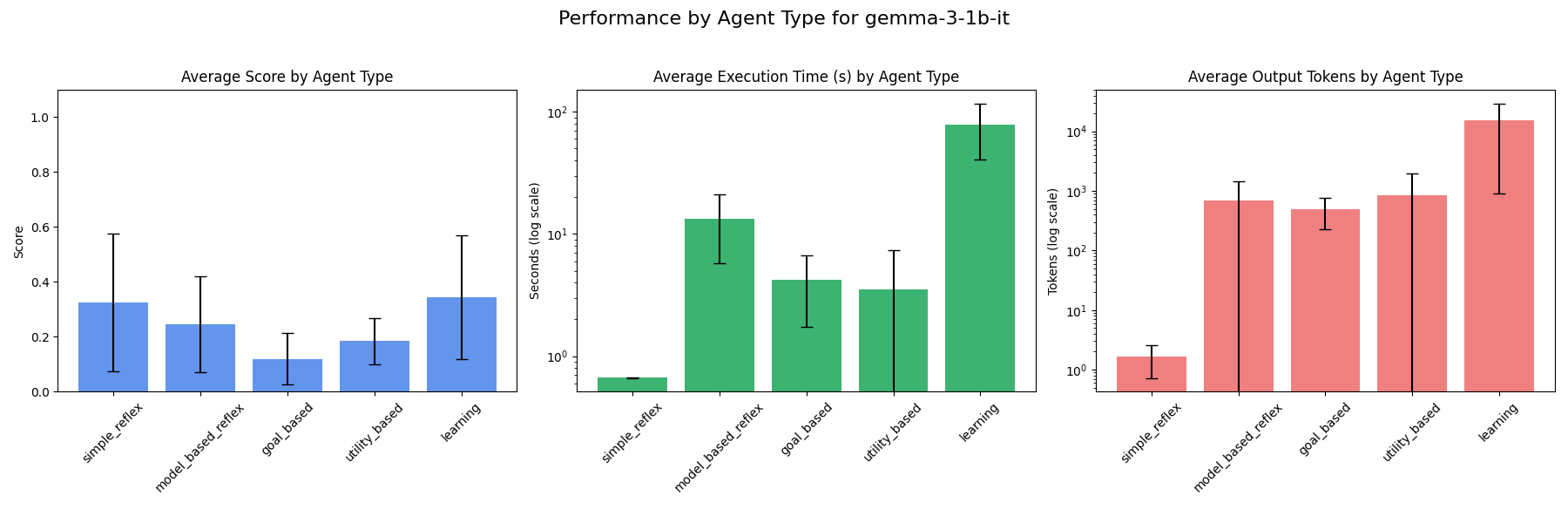
### gemma-3n-e4b-it
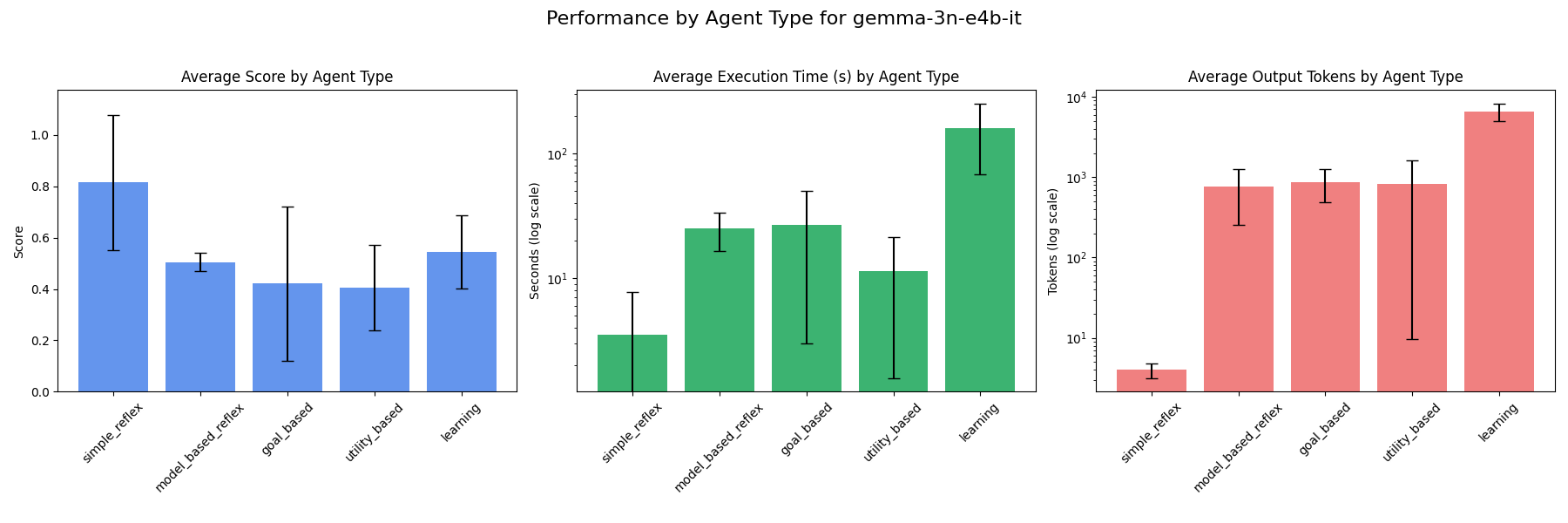
## Model Rankings
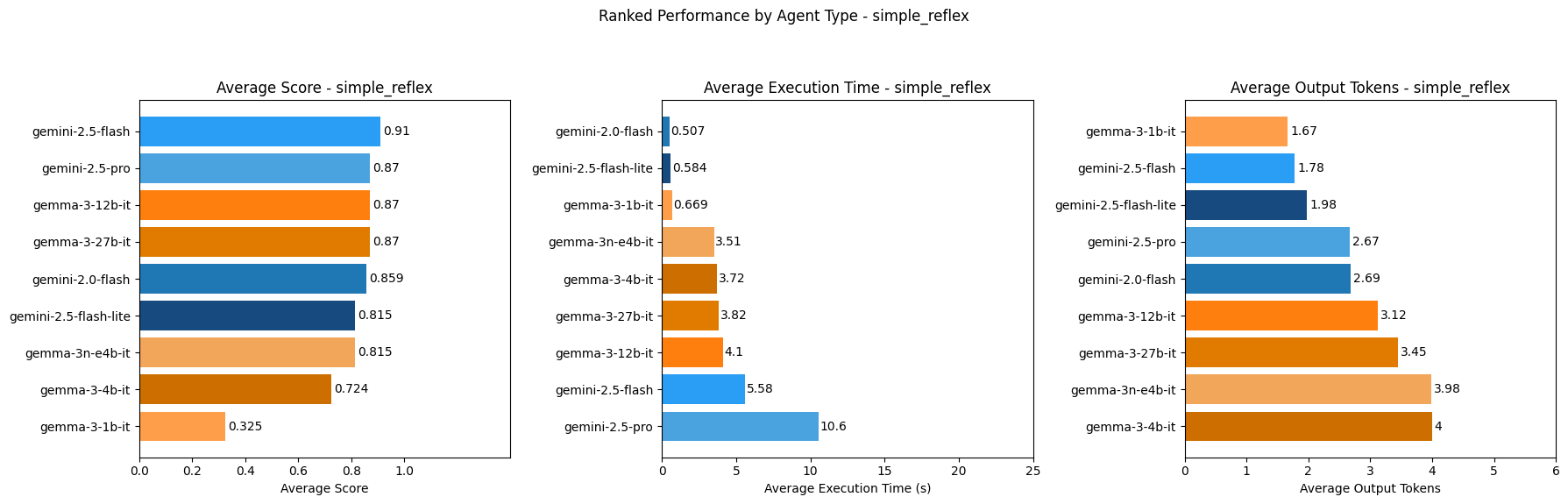
### Simple Reflex Agents Ranking
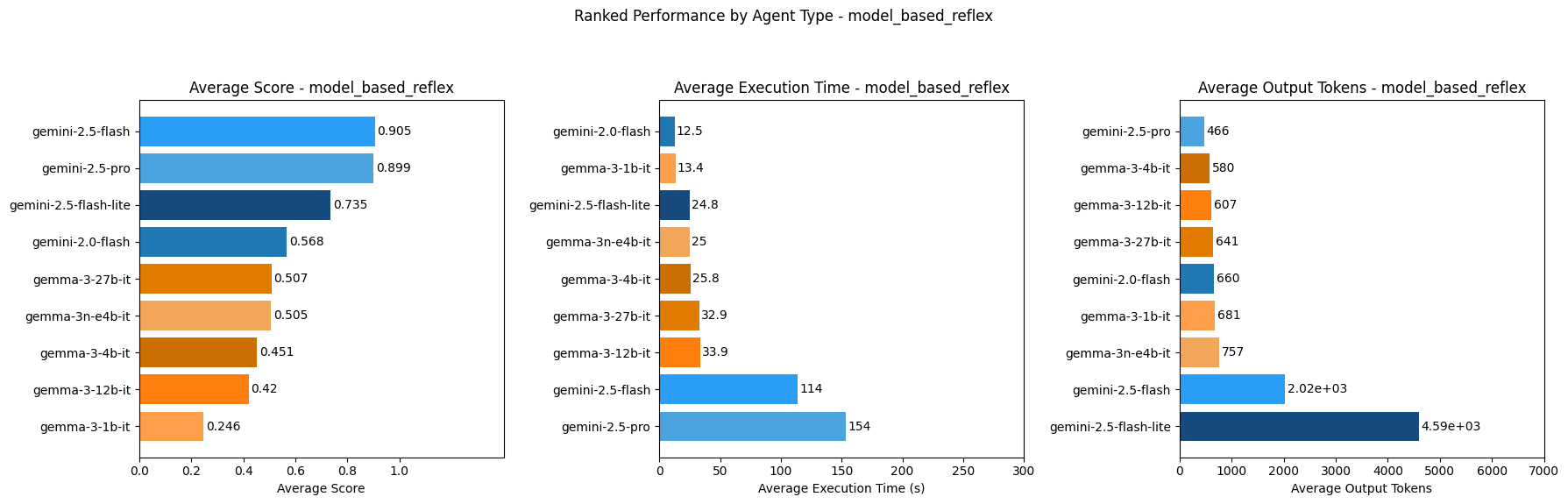
### Model-Based Reflex Agents Ranking
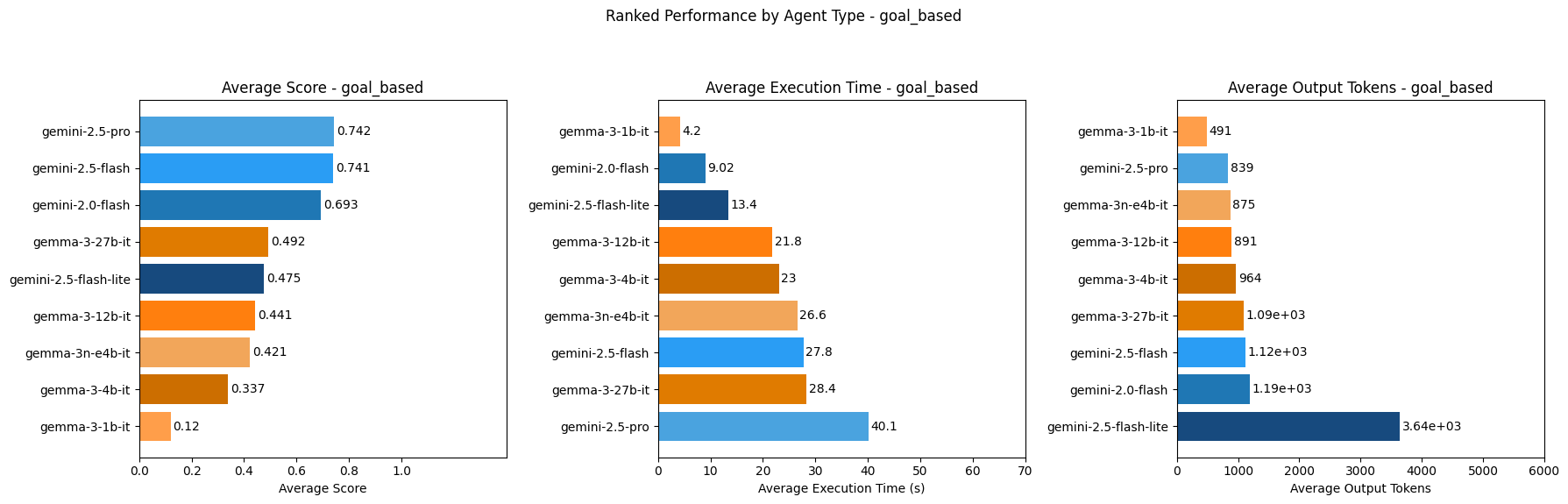
### Goal-Based Agent Ranking
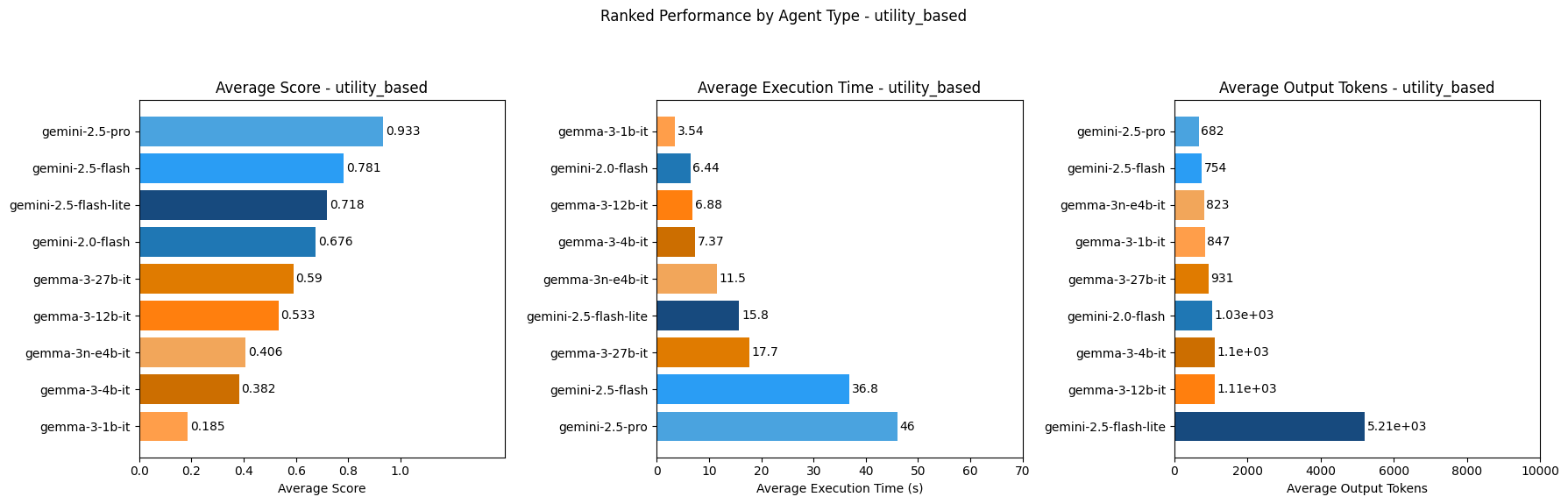
### Utility-Based Agent Ranking
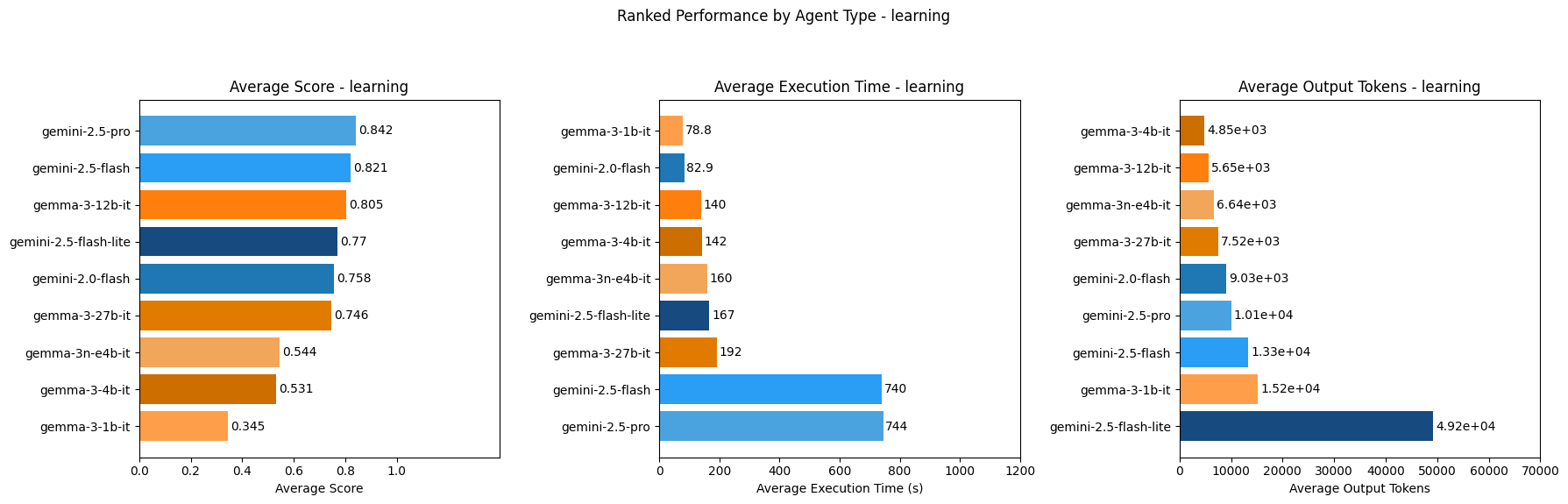
### Learning Agent Ranking
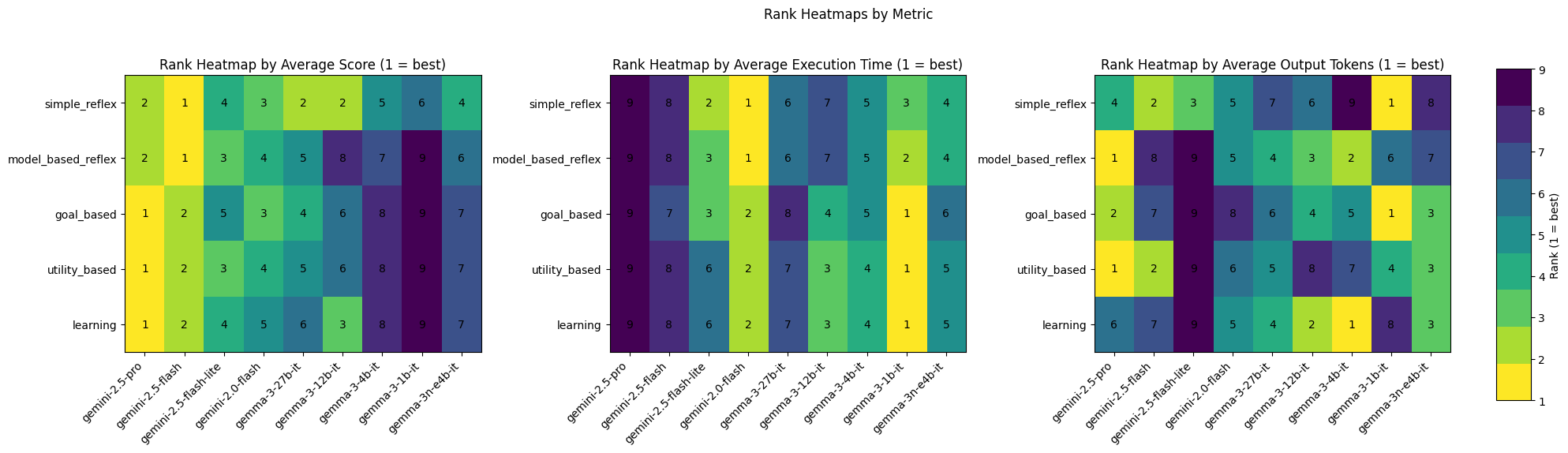
### Aggregate Rankings
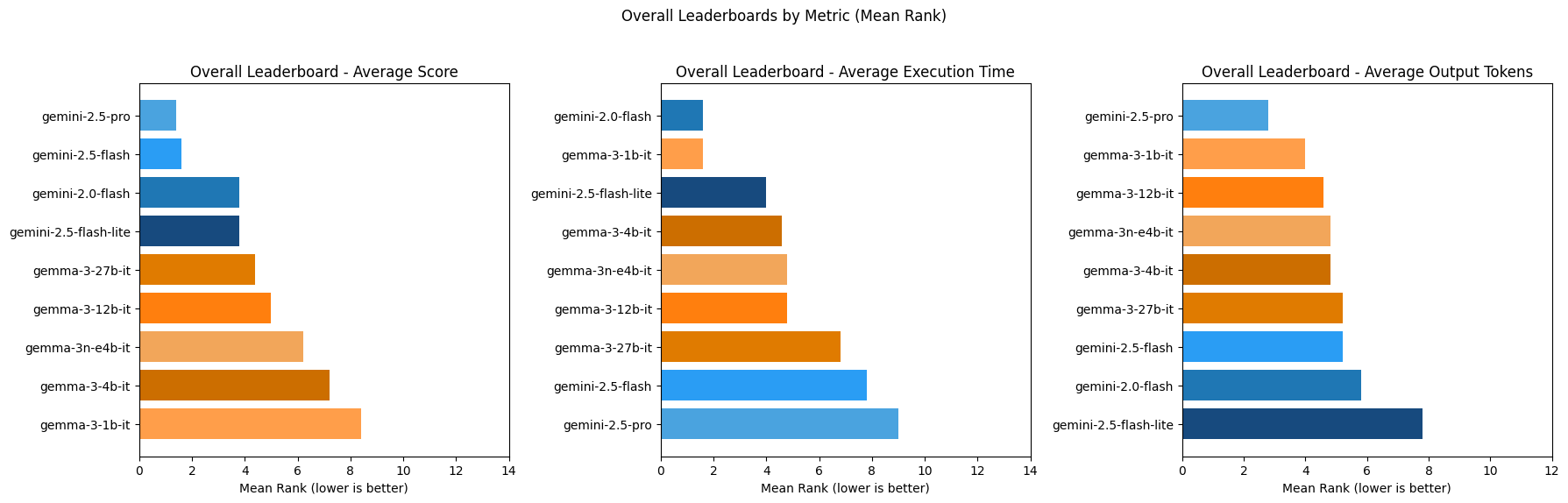
## Results by model (per-task metrics)
### gemini-2.5-pro
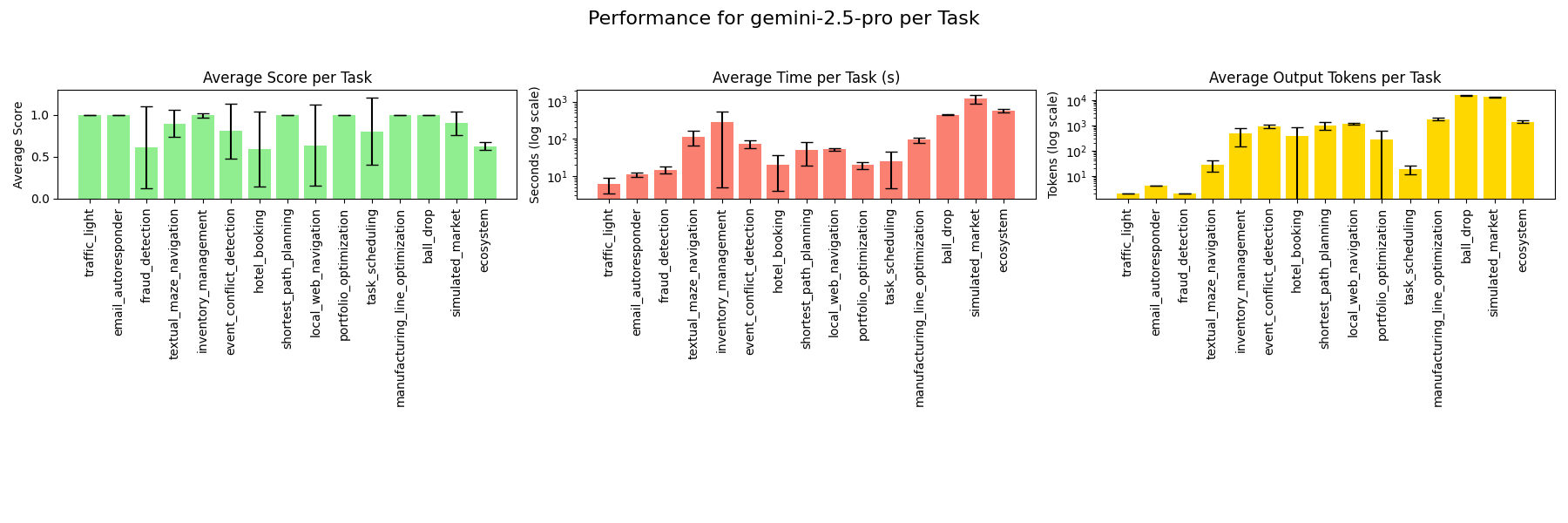
### gemini-2.5-flash
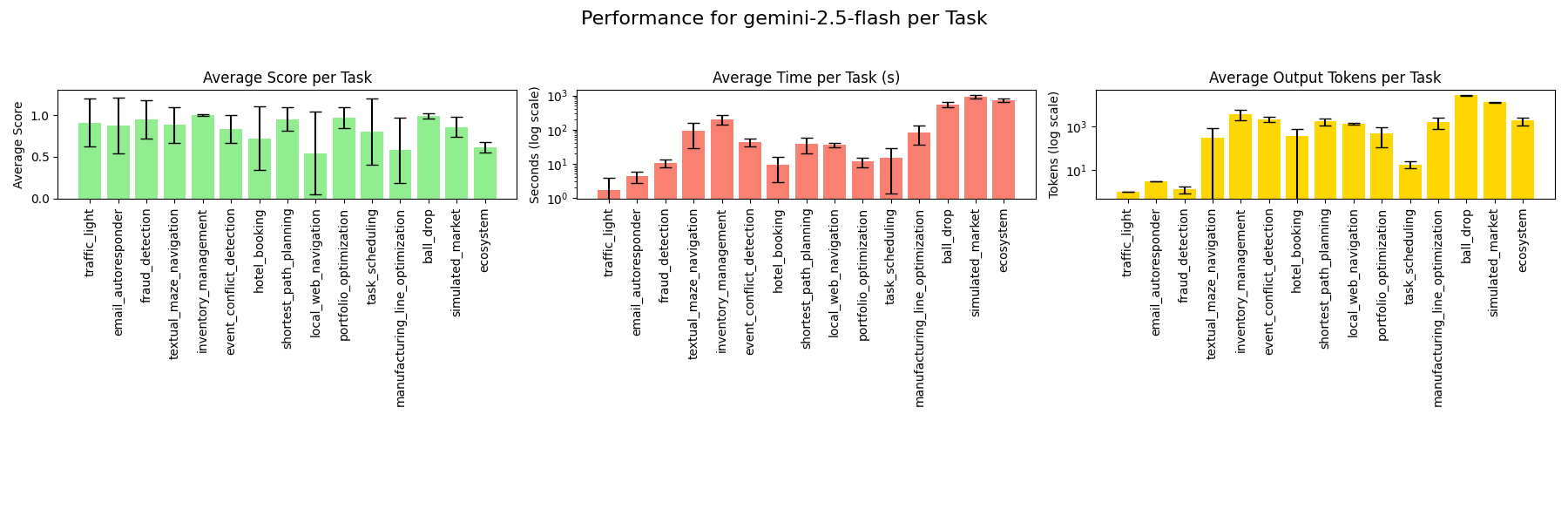
### gemini-2.5-flash-lite
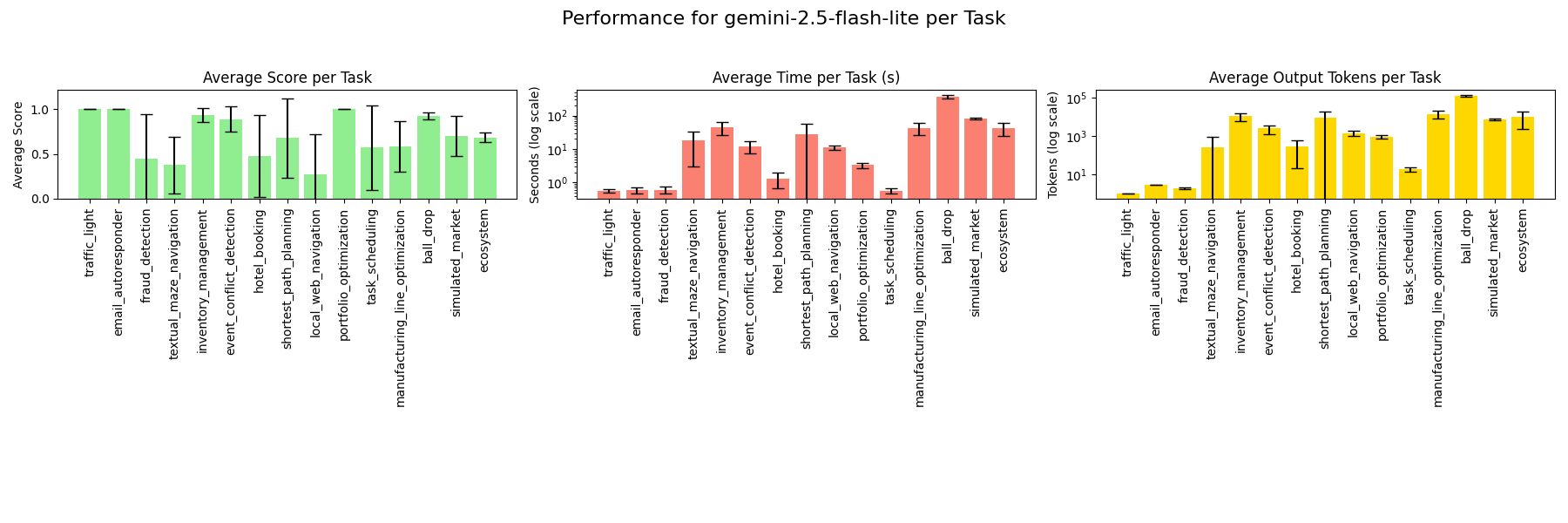
### gemini-2.0-flash
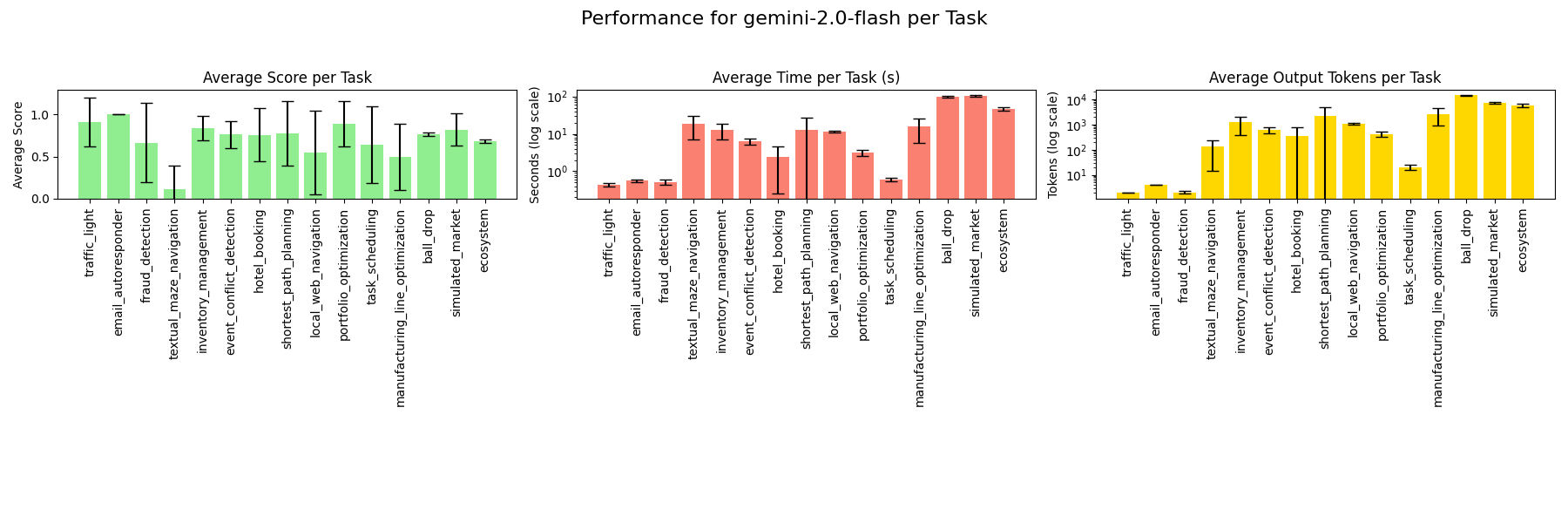
### gemma-3-27b-it
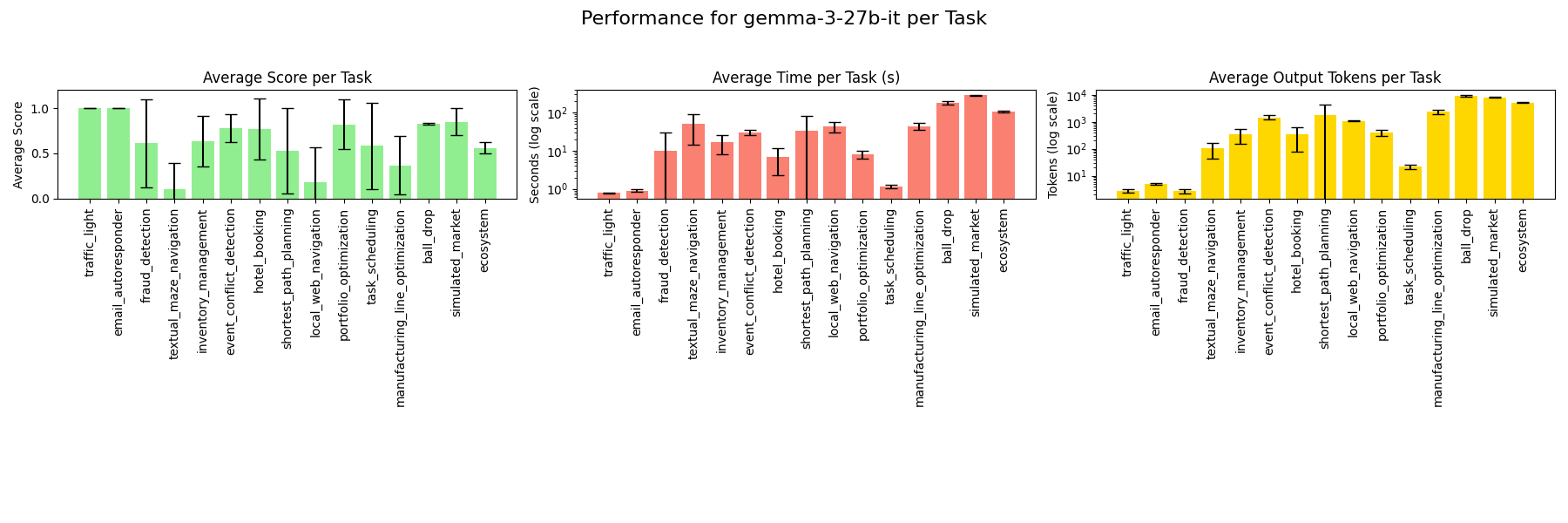
### gemma-3-12b-it
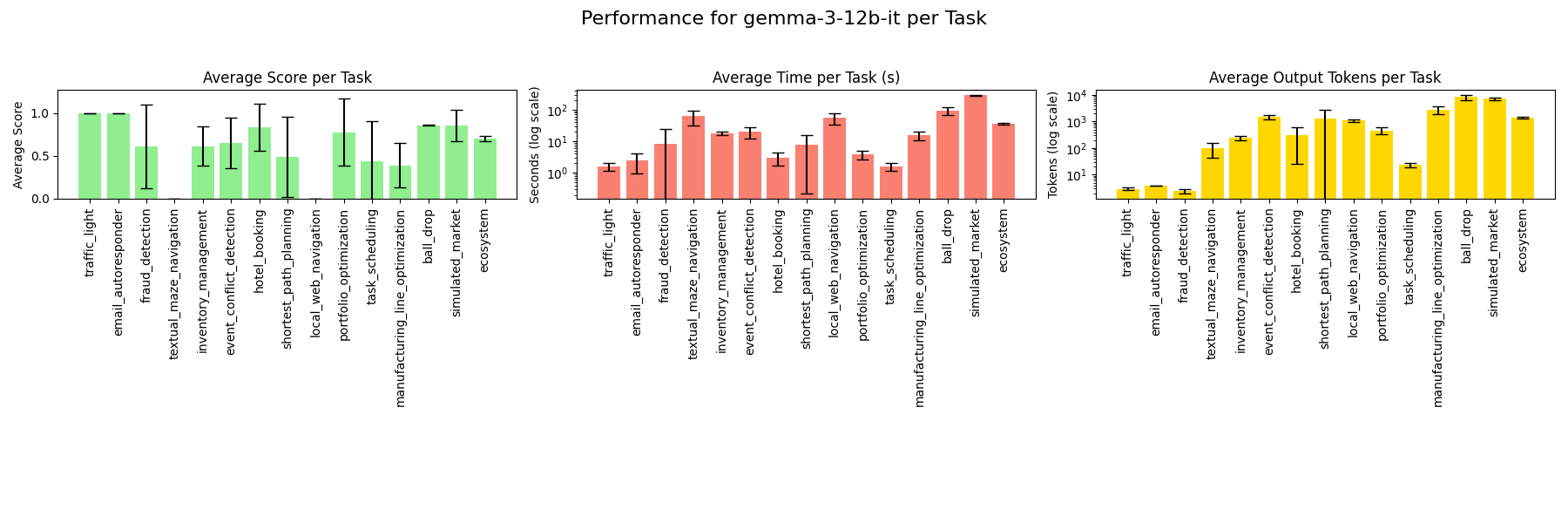
### gemma-3-4b-it
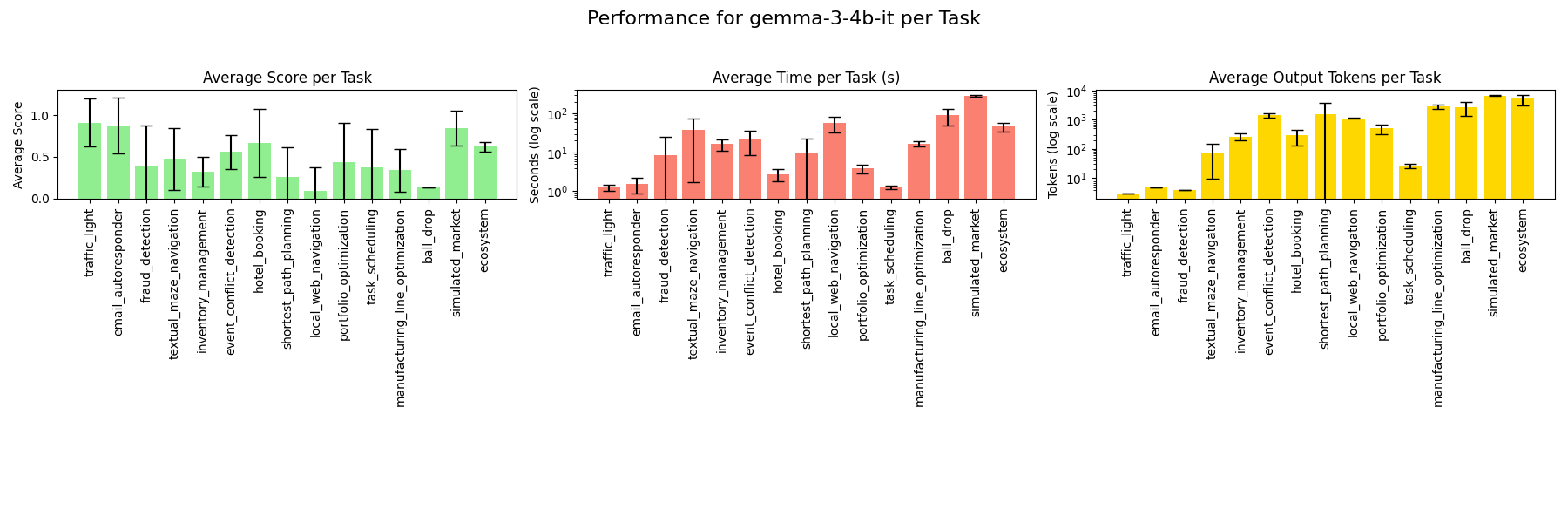
### gemma-3-1b-it
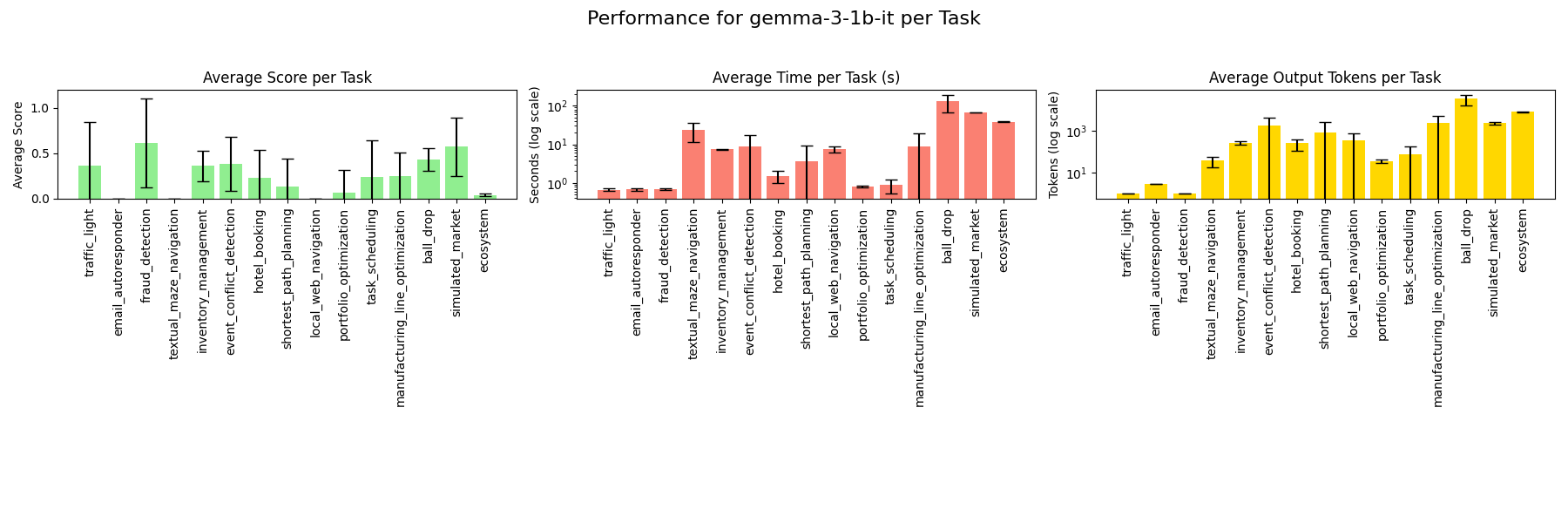
### gemma-3n-e4b-it
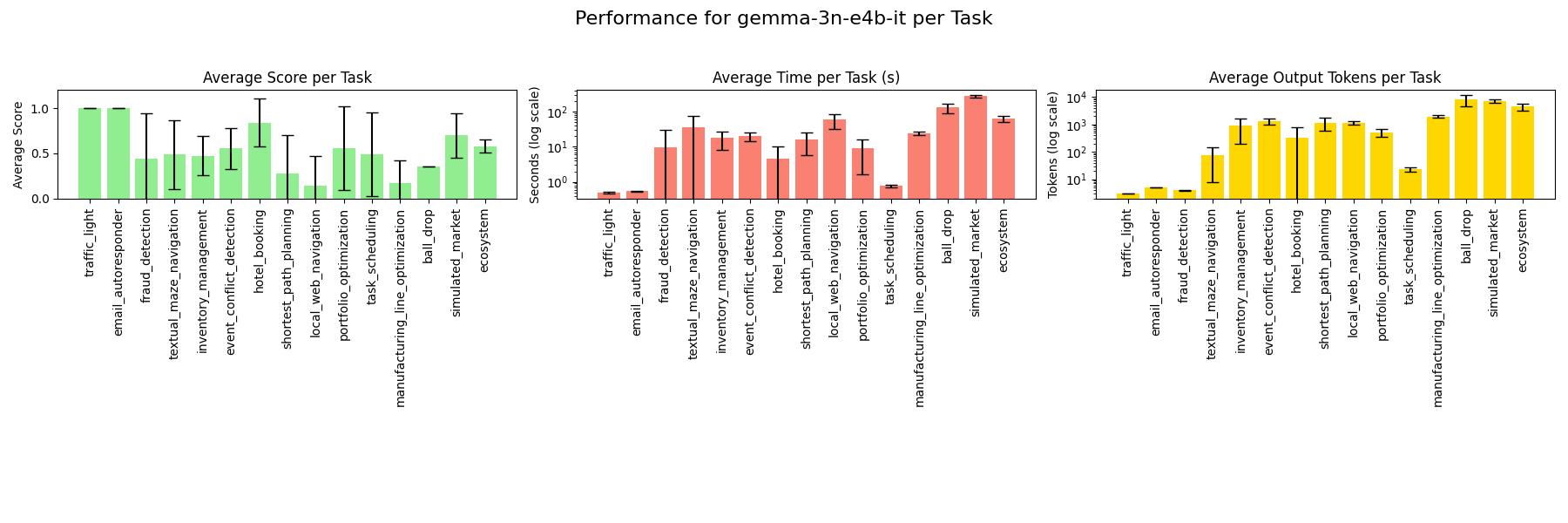
# Discussion
Gemini-2.5-pro ranks highest as goal-based, utility-based and learning agents out of all models tested in terms of score. This makes sense as Gemini-2.5-pro is the most advanced gemini model to date and would score highest out of the Google models tested as more complex agent types like goal-based, utility-based and learning agents.
Gemini-2.5-flash ranks highest as simple reflex and model-based reflex agents out of all models tested in terms of score. It is also faster as these agents types compared to Gemini-2.5-pro which is the second highest ranked model out of the models tested in terms of score for simple reflex and model-based reflex agents.
These models, however, are among the slowest across agent types and exhibit mixed rankings on average token output compared to other models tested. The best LLM for each specific use-case will ultimately depend on how important model competence, speed and cost are for the AI agent being built.
Out of the models tested, Gemini-2.0-flash ranks highest for speed for simple reflex and model-based reflex agents, while Gemma-3-1b-it ranks highest for speed for goal-based, utility-based and learning agents. So if speed is of highest priority in an AI agent, these models might be considered for the agent types they are fastest as.
Other constraints such as whether a model has to be run locally will also affect which models to choose based on these results. For example Gemma-3-12b-it seems like a strong choice for a learning agent run locally since it performed better than other Gemma models tested (as well as some Gemini models too) in terms of score.
# Challenges
The API traffic for different models can be inconsistent. This means we do not have a controlled environment. Although I did my best to control for API issues (e.g. by implementing API call retries and only including execution time for API calls that succeed when retrying), there are some external factors I cannot control such as API demand at any given time, which will affect execution time. The local testing capability of the benchmark that I implemented can help with this as it allows for a more controlled environment. However, running models locally will only work for open-source models. Thus, the choice to use model API calls or to use the models locally comes with their respective advantages and trade-offs.
# Future work
Implementing more agents/tasks for the core benchmark would be beneficial as the more tasks we have for each agent type, the more representative the results for each agent type will be.
Some LLM benchmarks and agentic benchmarks report instruction following error rates for tasks. Adding this to this benchmark would definitely be helpful.
Implementing parallel testing when calling the model via API can help speed up testing (assuming we don’t hit rate limits).
# Conclusion
The benchmark I implemented gives useful insights about what LLMs to pick when creating AI agents of different types. The results of testing in this project finds that Gemini-2.5-pro ranks highest as goal-based, utility-based and learning-based agents out of all models tested in terms of score, while Gemini-2.5-flash ranks highest as simple reflex and model-based reflex agents out of all models tested in terms of score. However, these models are among the slowest across agent types and exhibit mixed rankings on average token output. The optimal LLM choice for each specific use-case depends on how strongly model competence, speed and cost are prioritized for the AI agent being built and other constraints such as whether or not a model has to be run locally.
# Personal Takeaways
I’ve learnt a lot from this project, including how to implement different AI agent types as well as different task environments such as multi-step ones, ones involving meta-planning, and ones that use retrieval augmented generation or knowledge graphs. Furthermore I got more practice in implementing rigorous benchmarks and making more challenging benchmarks. Earlier scenarios I made were too easy for some models and I learnt to make harder ones later on. In addition, this project has helped me improve my design skills since a lot of the things I had to implement required careful thought and planning.
# References
[1] V. Barres, H. Dong, S. Ray, X. Si, and K. Narasimhan, “\tau^2-Bench: Evaluating Conversational Agents in a Dual-Control Environment.” 2025. [Online]. Available: https://arxiv.org/abs/2506.07982
[2] S. Yao, N. Shinn, P. Razavi, and K. Narasimhan, “τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.” 2024. [Online]. Available: https://arxiv.org/abs/2406.12045
[3] C. E. Jimenez et al., “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” 2024. [Online]. Available: https://arxiv.org/abs/2310.06770
[4] X. Liu et al., “AgentBench: Evaluating LLMs as Agents.” 2023. [Online]. Available: https://arxiv.org/abs/2308.03688
[5] N. Jain et al., “LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code.” 2024. [Online]. Available: https://arxiv.org/abs/2403.07974
[6] C. Stryker, “Types of AI Agents | IBM.” Accessed: Aug. 15, 2025. [Online]. Available: https://www.ibm.com/think/topics/ai-agent-types
[7] Y. Zhu et al., “Establishing Best Practices for Building Rigorous Agentic Benchmarks.” 2025. [Online]. Available: https://arxiv.org/abs/2507.02825